
OpenAIが新ベンチマーク「FrontierScience」を発表
2025年12月、OpenAIはAIの科学的推論能力を測る新しいベンチマーク「FrontierScience」を公開しました。
従来の科学系ベンチマークは選択式の問題が中心で、最新のAIモデルはすでに高得点を達成し”飽和状態”にありました。
FrontierScienceは、AIが本当に科学研究に貢献できるのかを、より正確に測るために設計されたものです。
FrontierScienceの概要
FrontierScienceは、物理学・化学・生物学の3分野にまたがる700問以上で構成されています。
問題の作成には、国際科学オリンピックのメダリスト42名と博士号を持つ研究者45名が携わっており、単なる知識の暗記ではなく、専門家レベルの思考力を問う内容です。
2つの評価トラック
評価は「オリンピアド」と「リサーチ」の2トラックに分かれています。
「オリンピアド」は、明確な条件のもとで正確に解を導く問題です。
「リサーチ」は、実際の研究現場に近い、自由度が高く複数ステップを要する問題です。
この2段階の構成により、AIの「問題を解く力」と「研究を遂行する力」の両方を評価できるのが特徴です。
GPT-5.2がトップスコア、しかし大きな課題も
OpenAIの最新モデルGPT-5.2は、オリンピアドで77%、リサーチで25%を記録し、Google Gemini 3 ProやAnthropic Claude Opus 4.5などの主要モデルを上回りました。
注目すべきは、この2トラック間に52ポイントもの差がある点です。
最先端のAIであっても、条件が曖昧な実際の研究課題にはまだ十分に対応しきれないことが浮き彫りになりました。
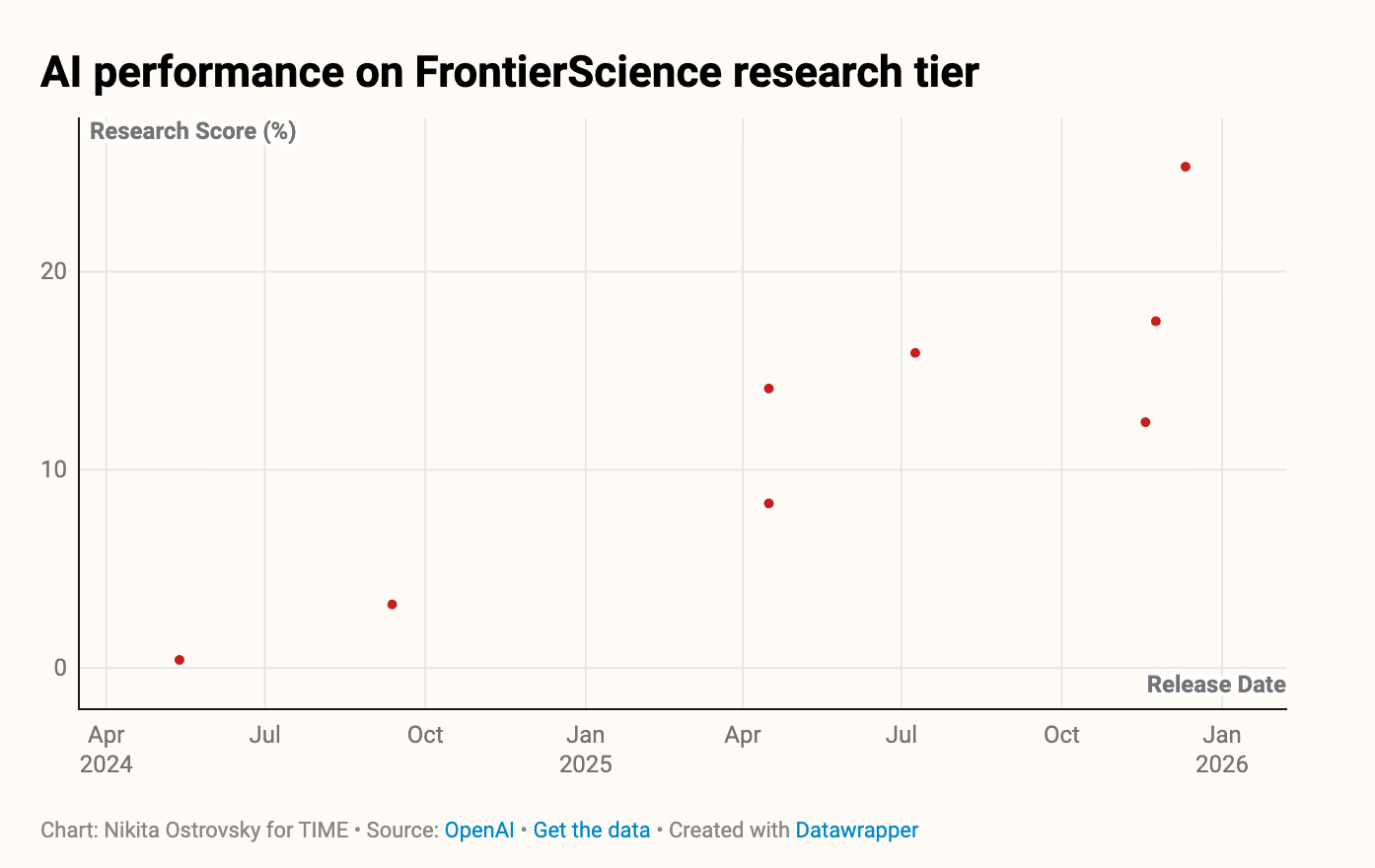
出典:OpenAI / Chart: Nikita Ostrovsky for TIME
従来のベンチマークは「卒業」レベルに
2023年に登場した博士レベルのベンチマーク「GPQA」では、当時のGPT-4のスコアは39%でした。
しかしわずか2年後、GPT-5.2は同じテストで92%を達成しています。
従来の基準ではAIの進歩を正確に測ることが難しくなっており、FrontierScienceのようなより高度な評価基準が必要とされていました。
科学者からの評価
研究機関Epoch AIのJaime Sevilla氏は「ベンチマーク・エコシステムへの良い追加」と評価する一方、「これだけではAIが実際の研究支援にいつ役立つかは予測しにくい」ともコメントしています。
また、理論物理学者のCarlo Rovelli氏は「LLMとの対話で良い科学ができると思い込んだ投稿が学術誌に殺到している」と懐疑的な見方を示しています。
ビジネスへの示唆
AIが構造化された問題を高精度で解けるようになった今、次の焦点は「曖昧で複雑な現実の課題にどこまで対応できるか」です。
企業がAIを研究開発に活用する際には、得意な領域と苦手な領域を正しく見極めることが重要になります。
オリンピアドとリサーチのスコア差が今後縮まっていけば、AIは科学研究の本格的なパートナーへと進化していくでしょう。
まとめ
FrontierScienceは、AIの科学的推論能力を「知識」と「研究力」の両面から評価する画期的なベンチマークです。
最先端モデルの実力と課題が明確に示された今回の結果から、AIと科学の融合がどこまで進むのか、今後の動向に注目です。
出典・参考リンク
AI Is Getting Better at Science. OpenAI Is Testing How Far It Can Go|TIME
Evaluating AI’s ability to perform scientific research tasks|OpenAI
FrontierScience: Evaluating AI’s Ability to Perform Expert-Level Scientific Tasks(論文PDF)|OpenAI
